Test automation: API-based model

Test automation enthusiast. I can't fix your TV.
The King Is Dead, Long Live The King
As technology evolves, industries are constantly updating their practices to keep up with the latest advancements. Old, although widely used technologies do have a shelf-life, thus at some point need to be exchanged for new, better-suited ones. An example of this is the use of the Page Object Model (POM) in test automation.
While POM has been an industry standard for years, it may not fit modern testing needs best. In this article, we will explore the shortcomings of POM and suggest an alternative approach, the API-based model.
What is Page Object Model (POM)?
The POM is a battle-proven and go-to industry-standard design pattern used in test automation to organize and maintain a test codebase for applications. Check out this article which encourages this as a best practice with a bunch of code examples. Or check this article with some visuals on how POM works.
All in all, POM involves creating page classes corresponding to the application's pages that contain all the different objects within those pages, aka WebElements, such as buttons, links, and forms. Those pages and WebElements are then used in test scripts to interact with the application under test.
Let's illustrate how POM works, in a stand-alone version, without any supporting tools:
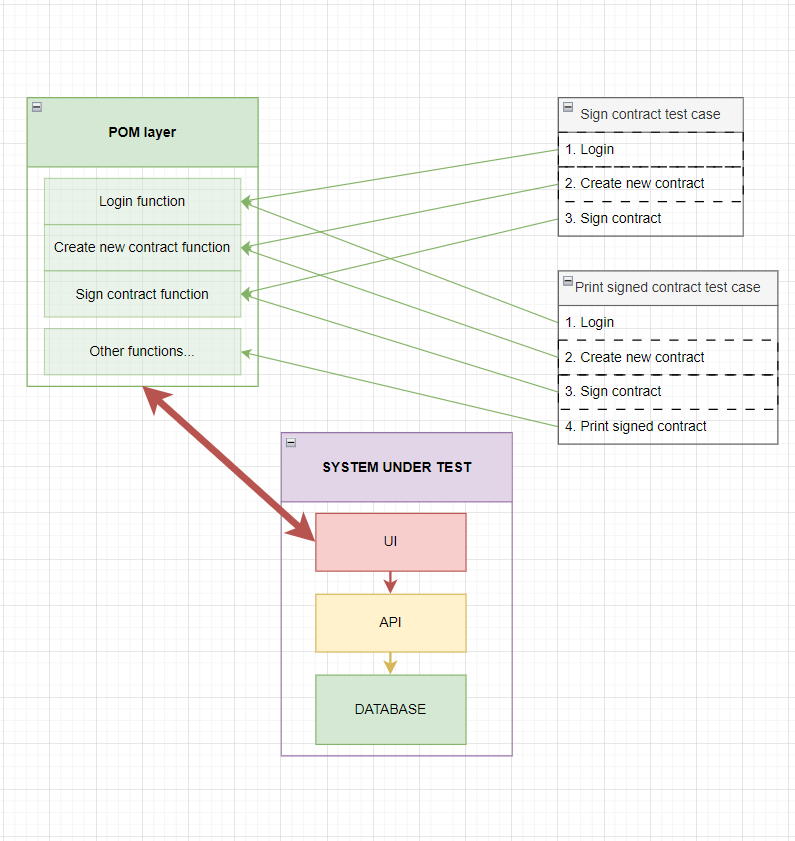
An abstracted contract signing and printing test case examples with simple steps were used to paint the picture (Login and Create new contract test cases were purposely omitted, they would behave in the same manner).
From the picture above you can see how POM acts as a proxy to the application creating a single point of entry for any actions performed throughout the testing. You should be able to spot a thick red line that highlights how POM relies heavily on the application's UI to do any test-related activities. Disclaimer: This is the main problem that we will challenge here. Here's an article from Cypress's blog that shares this opinion and provides another alternative to POM.
On another hand, countless online articles describe and praise POM, and they are not wrong. POM has many benefits and a few drawbacks, and let's face it - using any design pattern is better than no pattern, right?
Let's take a look at these benefits:
Test maintenance - when the application changes, any impacted tests must also be updated. POM gives you a single point of access, as all tests will share the same page elements. Fixing these elements is far easier than fixing all the affected tests.
Code abstraction - POM creates a clear separation between the test method and step implementation layers allowing you to write clear test methods with steps like
loginPage.setUsername("John")orloginPage.clickLoginButton(). All the technical details go into the step implementation (the POM) layer. For concrete examples, you may refer to this article.
What about the downsides of POM?
Even though POM has been widely used in the industry for a long time, it has some limitations that make it less suitable for modern testing needs, especially at scale. They force you to introduce additional tools, such as database scripts and yes, the API as well (we'll talk about this hybrid model below).
Here are a few problems that come together with POM :
POM is time-consuming to maintain - this model adds another independent layer to your testing framework that requires maintenance. This layer serves only one purpose, and creating and maintaining objects for every element on a web page is a time-consuming process. As web pages become more complex and dynamic, it can be quite challenging to keep up with changes and updates. This results in a codebase that is difficult to maintain and can slow down the testing process.
POM is time-consuming to execute - this model relies on the UI to perform any test actions, which can lead to very long test runs. Especially if the tests are started from the (almost) clean database and don’t rely on any pre-existing test data. Autonomous tests that don’t rely on prepared databases are next to impossible at scale.
POM is brittle in execution - every test will need to perform each action in the UI, which usually includes logging in, navigation, preparation, etc. Loading every page entirely and interacting with so many elements is bound to randomly fail at some point. This leads to flaky tests. This leads to test reruns, and... you get the picture.
POM has database requirements overhead - any large project using POM will require a significant amount of time to either prepare the database snapshot with necessary test data, prepare the database queries that will populate the database before each test run, or even resort to teardowns (which is a test automation anti-pattern by the way). Some will simply choose to rely on older, pre-existing test data and perform no cleanups whatsoever. All of these are setting up a path with many issues down the road. On the other hand, most projects will likely leverage API to populate the test data on the fly and, you've guessed it, these are baby steps toward an API-based model and strong steps toward the hybrid model.
Before we continue, let’s take a moment to appreciate one of the cornerstones of proper test automation: autonomous tests.
POM falls short in this area and is simply not enough on its own to foster true autonomous tests. Projects will have to rely on the API or some other solution to make this possible. Soon enough, projects end up with a hybrid mode of two layers which both require effort to maintain. In my opinion, this is a no-go.
The Alternative: API-based Model
Another approach to test automation is the API-based model. Although it's nothing ground-breaking or fresh on the market, if used and utilized properly it renders POM useless. Here is the golden rule of thumb for this model:
- Perform any action in the UI once, every other time use the API
Following this rule, this is how a cypress test case example would look like:
it('Sign contract', () => {
cy.login();
const contractData = { name: 'my contract' };
cy.createNewContract(contractData).then(contractId => {
cy.visit('/contract/' + contractId);
cy.contains('Sign contract').click();
cy.contains('Contract is signed').should('be.visible');
});
});
it('Print signed contract', () => {
cy.login();
const contractData = { name: 'my contract' };
cy.createNewContract(contractData).then(contractId => {
cy.signContract(contractId);
cy.visit('/contract/' + contractId);
cy.contains('Print contract').click();
cy.contains('Print successful').should('be.visible');
});
});
Notice how the sign contract action is only done through the UI only in the first test case? In the second test, the custom command was used that does this through the API.
Let's take a look at how those API commands would look in the commands.ts file (the API layer):
Cypress.Commands.add('login', () => {
const userData = { username: 'myUser', password: 'myPassword' };
cy.request({
method: 'POST',
url: 'api/login',
body: userData
});
});
Cypress.Commands.add('createNewContract', contractData => {
cy.request({
method: 'PUT',
url: 'api/contract/create',
body: contractData
}).then(response => response.body.id); // response.body.id will be returned as a result of this function
});
Cypress.Commands.add('signContract', contractId => {
cy.request({
method: 'GET',
url: 'api/contract/sign/' + contractId
});
});
This illustrates how an API-based model would work under the hood:
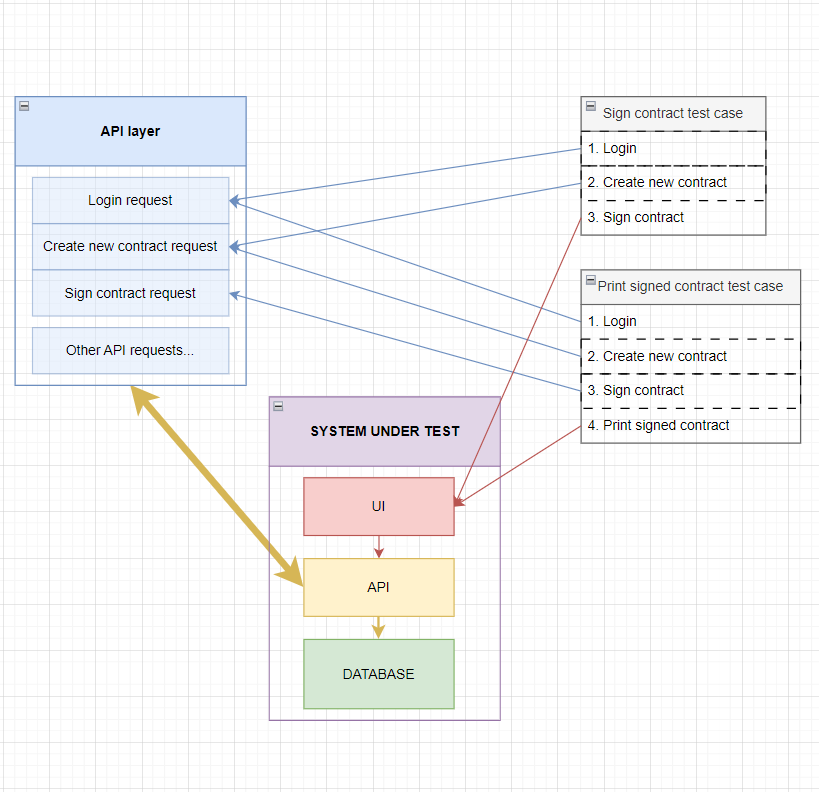
Comparing this image to the previous one, it's obvious how the heavy work is delegated to the application's API layer, while only the core of the test is done over the UI. This utilizes the application strengths more appropriately.
Let's analyze the above-listed benefits of POM, this time in the API-based context:
Test maintenance - respecting the golden rule will provide you with a setup that, just like POM, enables you to fix the problem in only one place.
Code abstraction - step implementation (the API) layer can be as abstracted as desired, and the same goes for the test methods layer. Add all the abstractions you like, whether using utility classes or functions.
Now let's compare the above-listed problems of the POM, and see if they are the same for this model:
API-based model IS time-consuming to maintain - this model also introduces an additional layer to maintain. Unfortunately, there's no way around that. There's one plus side however, the API layer can be reused for API testing, and vice versa. This enables you to save time and effort in test creation and maintenance. Additionally, it allows for a more holistic testing approach, where the UI and API can be tested with the same tool to ensure better quality, test coverage, and a more efficient testing process overall.
API-based model is NOT time-consuming to execute - because this model interacts with the application's API directly, it creates test data in a matter of (milli)seconds. It's blazingly fast. This enables the creation of necessary test data on the fly and makes the tests truly autonomous. Additionally, rerunning complex test cases which rely on a lot of test data is as simple as it gets, and maintaining them is quite straightforward.
API-based model is NOT brittle in execution - During test preparation, this model doesn’t rely on a browser to fully render a web page, it doesn't need to load additional resources (like images, JavaScript, or CSS files), nor does it need to interact with the page in any sense, chances for something going wrong are drastically lower, making it extremely robust. Any frontend issues in the application won't stop your other tests from executing. The brittleness of the page is only contained within the core of the test case.
API-based model does NOT have database requirements overhead - unlike POM, using this model you are free to choose if you are going to start with a clean database and build up all the test data on the fly or use some sort of prepared environment. This model won't stand in your way.
And finally, let's mention some drawbacks that this model has, that POM doesn't:
Test data format - The biggest flaw of this model is that all test data for test preparation has to correspond to the existing API specifications. This can be unintelligible and difficult to comprehend or write, mainly depending on how well the API server was written by developers or how familiar with JSON syntax you are.
Mobile testing - this model would only be suitable for web applications, which use a standardized REST interface. Mobile testing, especially when it comes to native apps, should still fall back to POM.
Client-heavy applications - some client-heavy applications that do most of the work on the client side are not suitable for this model, as you cannot use the API to prepare the environment upfront.
Online resources - there are no (or at least I couldn't find any) other resources online to confirm the claim that this model is indeed better suited than POM for testing the standard web applications.
Conclusion
In environments where projects scale fast, and test frameworks grow exponentially, where the shift-left paradigm moves the testing efforts ever-so early in the development process, the time has come to challenge the old ways, to give a chance to new, modern solutions.
The API-based model provides a more versatile, efficient, and robust approach suitable for multiple testing needs. As technology continues to evolve, it's important to adapt testing practices to ensure that they remain effective and efficient, to make the testing and thus your (work) life easier.
Use the next opportunity to try out this model, and let me know how it worked out for you.
Happy testing!