Reference Stories
A helpful guide on how create common understanding!

Why? What is the Problem?
As a service contractor with many projects, it's not unusual that team constellations change. This can have many reasons: Sometimes projects come to an end, sometimes people just want to evolve and learn new things, and sometimes we have to react to unforeseen changes. As new team members join the team, the understanding of the complexity of a user story starts to differ and this can lead to lengthy discussions. In many cases these discussions are about the right amount of story points, you might have heard it already: "For me, that is more of a 13" or "I would say that's rather a 21", and so on. That happens because the numbers do not reflect someone's understanding of complexity - and this is where reference stories come in.
What are Reference Stories?
Reference stories are already estimated & implemented user stories, which serve as a reference if discussions in your Backlog Refinement tend to get unproductive. They are elaborated collaboratively by the team members in a game, which I am going to explain to you in a minute. Reference stories create a common understanding of the correlation between estimation and complexity. In our case, each Fibonacci number has one reference story assigned, which we can refer to if we can't decide on an estimation.
Action: Let's find our Reference Stories!
Some prerequisites for the game:
Choose 15 to 30 user stories and make sure they have different estimations. I used a simple Jira Query which filtered my stories on Status and Story Points.
The stories you choose as your candidates should be already implemented and in status Done. This ensures that you know how much effort you actually had.
If possible: Try to collect stories where most of the team members participated in the original estimation, the stories shouldn't be too old. Therefore you have a higher chance to interpret the story correctly.
You are not going to compare the new value with the old one. See it as a recalibration of your estimation.
Try out our Reference Stories template in Miro
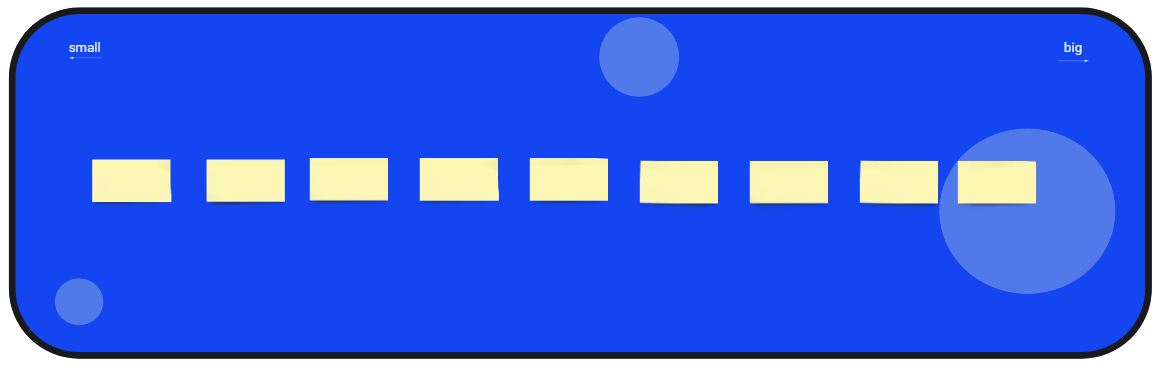
Part I - Sort the Stories horizontally
We now have a pile of user stories with different estimations and our goal in Part I is to sort them horizontally from small to big. At this stage, it doesn't matter if one story is definitely bigger than another. You don't have to be too precise yet, we are going to sharpen them in the next round. What is important is, that we have established a horizontal order with our user stories and got a consensus about that.
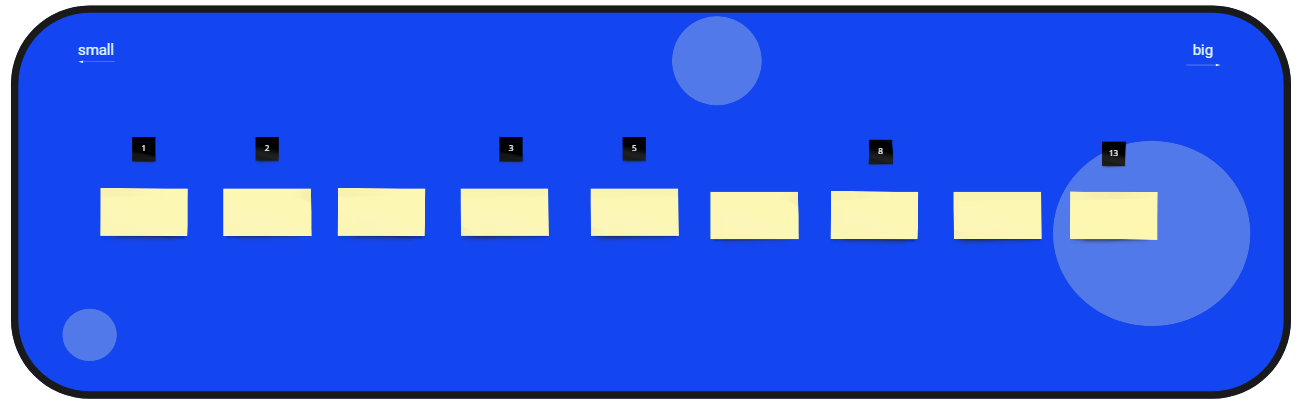
Part II - Estimate the Stories
The next step is to discuss each story from left to right and our goal is to assign them to Fibonacci numbers. A good way to do this is by creating categories/buckets. Notice, that you do not have to estimate the story like you would do in your Backlog Refinement, you did that already. It is more important to find the right category/bucket for each story. Stories per category/bucket might not necessarily be the same size but are somewhat comparable. Start with the smallest story, propose a category, and discuss the decision with your team members. The smallest story on the left doesn't necessarily need to be a "1", it might be a "2" or maybe even a "3". This depends on the story you have chosen for this game. After you've estimated the first story, put the sticky in the correct category/bucket and move on to the second, discuss it, and move to the next one. Try not to look back on the original estimated value and focus on doing the discussion from scratch, together in your current team constellation. That is important to fulfill our overall goal: To have a common understanding of complexity. You might run into heavier discussions about the estimations but that is okay, find an agreement within your team. After estimating all stories, your board should look something like this:
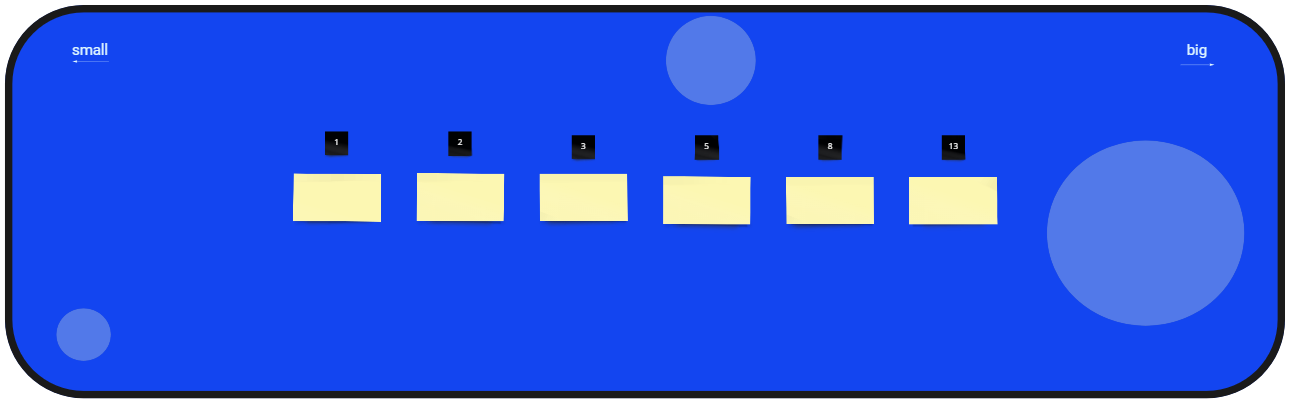
Part III - Choose your Reference Story
Congrats! You have all your Reference Stories assigned to an estimation. Now there is one last step left. The goal of Part III is to decide on one user story per Fibonacci number. These Reference Stories should help you in case you can't get an agreement in your Refinement Meeting. To reduce the room for more discussions and uncertainty, I recommend having only one story per estimation available, so in round III, choose the ones you want to go for.
And Then?
In the future you want to fall back on your team's Reference Stories when you have troubles in your Refinement Meeting, so document them somewhere in your project space. You will see, the longer your team members work together, the better their common understanding gets. If your team gets adapted, repeat the game and create shared understanding again.
Conclusion for CLF
In the last month, our team grew by five people and the Reference Stories helped us to create a common understanding of how we estimate complexity. I decided to use this method in order to react to lengthy discussions within our Refinements, which turned out to get unproductive. It is important to note, that Reference stories do not remove all your discussions - and they shouldn't! We are living in a fast-moving world and IT services are more popular than ever. Team changes will happen in the future. My next step is to spread the word throughout our company directly to our project leads, establish a common practice and adapt them if necessary. I hope this helped and if you have any questions or inputs, let me know!