On Testing
I have seen strong obsession with terminologies when it comes to testing, like integration tests versus unit tests, should there be mocks in unit tests and so on. Working with people who care to improve is a bliss. Nonetheless, being too focused on those concepts might not be a good idea. The essence of testing, the thing that actually matters, stays the same no matter the concepts built on top of it.
The Purpose Of Automated Tests
Before starting with this topic, we must first be clear what tests are for, the “why” to test. In order to answer that, let's imagine a code base without tests. The growth of needs, change of requirements and alteration of environment in production forces the software to be modified to fulfill the previously uncovered areas. How can the stability of the program be ensured, when the code gets modified? What proves existing features are still working the way they are supposed to, when the programmer touches some long forgotten algorithms used in the code base? That is what tests are for: To ensure the quality and stability of the software.
What is the quality of software? Is quality and stability the only characteristics tests are good for? For the brevity of this article, I will define the quality of the software as fulfilling all the requirements. Other properties of tests, TDD, performance testing and others won't be mentioned here either since they are not relevant.
This goal can be achieved in many ways. One of which is to have a test protocol and manually go over it every time something is modified. However, this approach does not scale. Why? The massive investment of manpower is the limiting factor. When it comes to repetitive tasks, humans are error-prone, slow, expensive and have inconsistent output depending on the weather of the day. So what can be done when humans are real pains to deal with? Yes, doing what our ancestors have been doing for a long time: Automation.
How does a test look like?
In order to draft the properties a test should have, we need to look into how the process of working with automated tests look like. There can be a lot of them in any given project. They get executed and some might fail. In case of failure, the programmer wants to know which ones need to be looked into in conjunction with getting to the root cause as fast as possible. The important questions are where the failed tests are, what (or which requirement) failed, and why it failed. With that nailed down, we can think of how to make it easier for the programmer to get this information.
The testing framework already provides the answer for the Where-question by logging or highlighting the failed tests in some way. So as an author of tests, the only things to care for is to provide the What's and Why's. The What-question is all about the name of the test. It should be descriptive enough that the programmer knows the context of the failure. Looking into the implementation of the test is of course an option, but needs more investing to understand and process through than a good test name. The next step is to provide the answer to why the test failed. The reason is highly situation dependent and because of that, hard to answer at the time the test is written. What can be done is to structure the test in a way so investigating the root cause becomes efficient. The below-mentioned methods are some of the best practices to achieve that efficiency.
Given-When-Then
Naming is hard. If there are 500 tests in the project, how can we ensure the test names are descriptive? Having some kind of pattern will help a lot. That is when the Given-When-Then paradigm comes into play. First and foremost is the test name: Given environment When executing action, Then the result is X. With the help of this pattern, the most important pieces of information are contained within the test name. In addition to that, Given-When-Then also tells us how a test itself is, or should be structured. First is the setup part (Given), afterwards the execution (When) and lastly the checks for the result (Then).
- given year 2001 when checking for leap year then return false
- given year 1900 when checking for leap year then return false
- given year 2000 when checking for leap year then return true
- given year 2004 when checking for leap year then return true
- given year 1 when checking for leap year then return false
- given year 0 when checking for leap year then return true
- given year -1 when checking for leap year then return false
- given year -4 when checking for leap year then return true
A common discussion I often hear is about the topic of how the tests should be grouped when there are many of them in a spec file. Should it happen by Given or by When? The test code should be structured to aid the developer in finding the answers for the What and Why. The essence of the discussion is which way of grouping fulfills that purpose better. What we test are not the environments, the Given section, but the When. We do not create environments and ask what the output of all kinds of actions should be, but which environments do I need to craft for the action, so I can test all kinds of aspects of it properly. The answer is grouping by When. The group structure will look like below.
when checking for leap year
- given year 2001 then return false
- given year 1900 then return false
- given year 2000 then return true
- given year 2004 then return true
- given year 1 then return false
- given year 0 then return true
- given year -1 then return false
- given year -4 then return true
KISS - Keep It Simple Stupid
Given-When-Then is nice. Nonetheless, it is usually not enough, especially when abstractions, DRY and other principles get applied in the name of clean code. We want to find the answers to our questions when a test fails. Do all of these principles help us achieve our goal? Abstractions are not without cost. They add one layer of complexity, and complexity makes the code harder to understand. If something makes the situation worse, then the opposite makes it better, right? In this case, yes. The key here is simplicity. DRY? Inheritance? Higher order functions? Loops? None of that are allowed unless skimming over the code would be harder without them.
DRY creates dependencies by merging existing code into one place. If I modify the extracted code, then two or more tests will change with that. Is that really something desired? Inheritance hides logic behind super classes. How should the developer find the reason for the failed test without jumping around in the inheritance chain? Higher order functions hide complexity in the function body. It causes the same problem as inheritance. Loops make it harder to understand how many times and what exactly is executed each time at a quick glance.
The aforementioned patterns are not the only ones where the drawback is bigger than the gain for test code. They are mentioned because they are the most common pattern I see people use. How can we manage the complexity in case the testing code becomes unruly then? The Given- and Then-blocks are the only places where any kind of abstractions are allowed. The When-block is where you execute the code you want to test. Any kind of sugaring is not allowed. For setting up the environment, only simple functions should be allowed as abstractions. In case the result is too complex to assert for with the utilities provided by the testing framework (or other libraries), then custom assertions can be created. Custom assertions should still conform to the patterns of the testing library used, e.g., taking in a structure as expected output or simple and clear naming like "isJsonStringValid".
On Mocks
A concept not foreign to the majority of those who have written tests before, are mocks. They are substitutes for dependencies in tests, so those dependencies do not need to be used. Let us go back to the first paragraph of this article and take a look at what tests are for: To ensure the quality and stability of the software. This begs the question whether mocks are helping us achieve that goal. Since mocks are so common and widespread, of course it helps us do that, does it not? Is that, however, really true?
Assume the following case: I mock away a dependency and in 2 months that very dependency changed its implementation to return something else given the same input. It gave me 4 as return value before, whereas it returns 6 now, but I have a check for throwing an error for any values bigger than 5 because we don't accept anything bigger. I didn't know about it, so I didn't change the mocks, or better said the person who changed that implementation forgot to change the mocks too. It might not even be known that there is a mock for it in a certain test. Now, is my test still doing what it is supposed to do?
The point of a test is to ensure the quality and stability of the software. If I am not testing code that will get run in production, then I am not fulfilling that purpose. The very nature of mocking actually works against our goal! Ideally speaking, there should never be any mocks anywhere. Of course, reality is different. Mocks solve real world problems.
Assume the following case: I need to make a network call to the backend. This means I have to have a running backend instance, which most probably also requires a database and potentially some other backend services too. Starting all of that will simply take very long, and the calculations and communication overhead will make everything even slower. A test suite that takes a lot of time to run is simply not acceptable, since the feedback loop is too long. This is where mocks come into play: The backend gets replaced with a dummy, and we return some predefined answers for the calls we need.
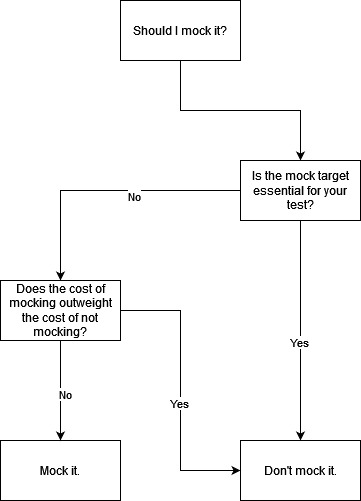
Isn't it confusing? Mocks work against the reason tests exist, but sometimes we really require them to make our life easier. That means mocks are good after all? When should mocks be used? Are there any criteria for that? Which in turn leads us to the cost of mocking and not mocking, namely the following:
Setup Cost
How much does it cost to set up all those dependencies? Setting up the backend on the CI for frontend might not be easy for multiple reasons. Mocks can have varying costs too. Sometimes noops (no operation) is enough, and sometimes more nuanced answers should be returned. It depends on the mock.
Runtime Cost
Runtime cost is further divided into start-up cost and the cost to call it. Starting dependencies like backend servers and databases can take some time. Some frameworks like Spring do a lot at runtime, which can blow up the start-up cost too. The calling cost is how long it takes for the dependency to return results when requested. Mocks are dummies, so their runtime costs are very low.
Maintenance Cost
In case of dependency updates, how easy is it to keep the current level of quality and stability of the test? It might be just a change in version string when using the actual implementation, or no action is required since that dependency is in the same code base. Mocks on the other hand need to be checked by hand if they still conform to the behavior expected from their respective targets.
Not all costs are equal, though. The human factor in maintenance is very big, making it weigh more than the other two costs. If mocks should be preferred in certain situations is simply a calculation of costs: Sum of all costs of using the actual implementation compared with the sum of all costs of using mocks. Whichever one is smaller is the one you want to go with.
Mocking in Unit, Integration and E2E Tests
With all that said, how does it work together with existing terminologies? When should one mock in a unit, integration or E2E test? Surely the testing pyramid is not new to you, am I correct? 😉
An E2E test ensures the software in its entirety works as expected, just as if it runs in production. Since E2E tests are for the whole software mocking anything there is a bad idea. Are you sure it will also work in production if, e.g., the backend is mocked away?
An integration test ensures the combination of units, which makes up a bigger part of the system, is working correctly. The units in integrations tests are pieces of code from the same code base. In this case mocking away external dependencies like backends, databases etc. is fine if needed.
A unit test ensures that one single unit does what it is supposed to do. It is debatable how to define the unit: Is a class/function/… with all its dependencies a unit or without them? If it is the former, then what is the difference between that unit test and an integration test? If it is the latter, then shouldn't I mock away all the dependencies since they don't matter? On the other hand, according to the aforementioned scenarios and costs for mocks, that should not be done. What is what now?
Let's take a step back. Take a deep breath and ask ourselves the question: What do we actually want to achieve? The end goal is clear: To ensure the quality and stability of the software. How do we ensure the quality of this piece of code the best? Right, mock only when its cost is smaller than not doing so. If it is called an integration test, then so be it. If it is called a unit test then so be it too. Does a unit also include its dependencies or not? The categorization is not important here. Terminologies can help us reach our goals, but they are not the goals themselves. Remember the first sentence of this article?
Mock Management
Alright, we understood the pros and cons of mocking and when to apply it. The biggest drawback of mocks is the maintenance thereof. The setup cost is a one time payment, so in the long term it does not amount to much. So is there a way to reduce the maintenance cost? The answer is yes.
Use Upstream-Provided Mocks
It is not our responsibility anymore if the mocks are from the dependency maintainer. 😉 One example would be ReadyAPI for OpenAPI.
Use Existing Mocks
Have only one mock per dependency in the whole code base, and use that in every test in need of it. This way, the need to go through all uses of that dependency is not needed anymore.
Consistent Mock Location
Either place all mocks in one folder or directly where the actual implementation is. Removing the barriers to updating the mock will decrease the frequency of forgetting doing so.