

Moving Elasticsearch into Kubernetes

Search for a command to run...
No comments yet. Be the first to comment.
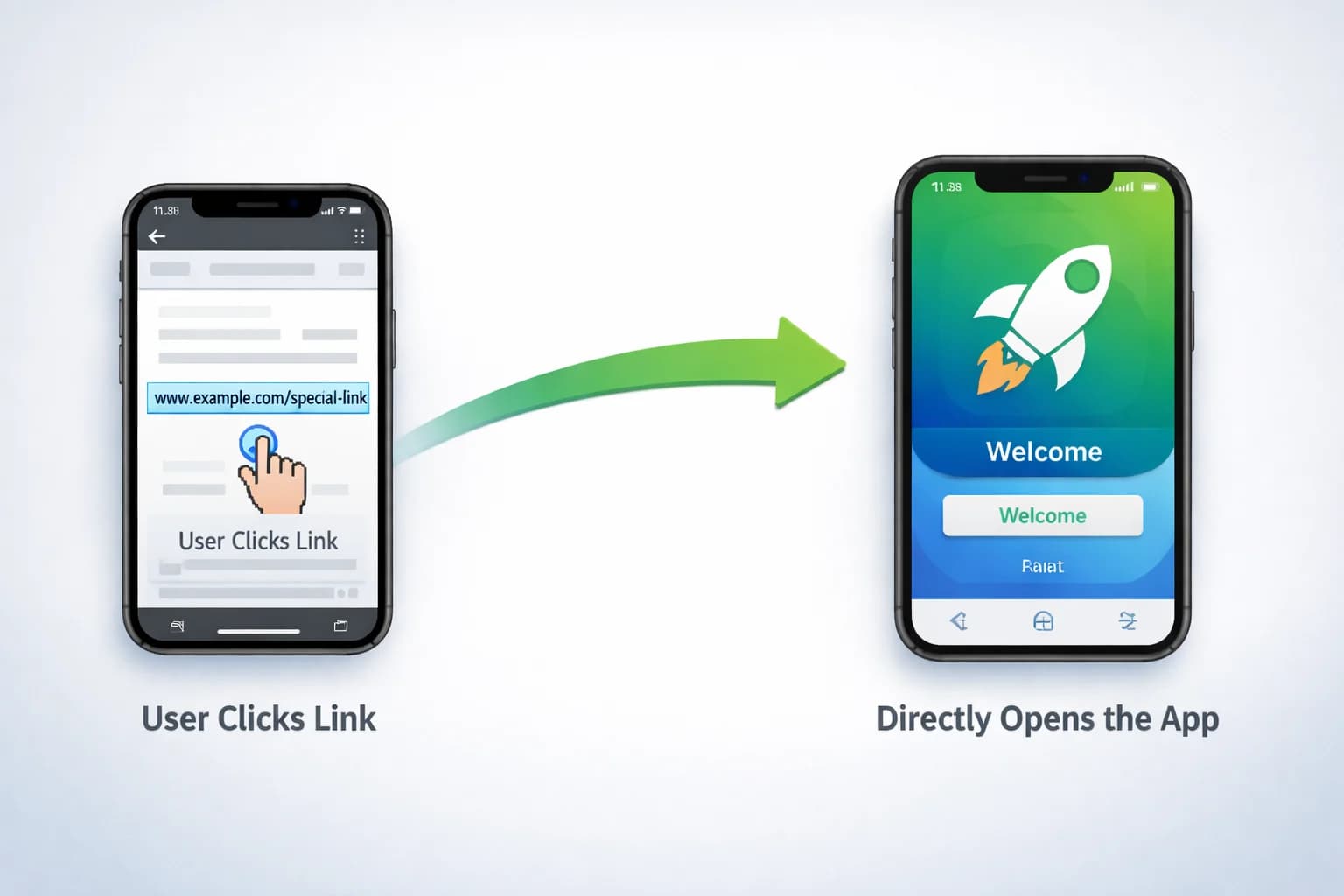
TL;DR This post explains how iOS Universal Links work and what is required to implement them. It covers how to handle incoming links in an iOS app, how to create and configure the Apple App Site Association (AASA) file, and how to correctly host the ...
TL;DR The Page Object Model (POM) is the industry standard, but it is not easily scalable. The Flow Model Pattern improves upon the basic POM, offering a perfectly balanced solution that is not overly complex yet still scalable. The Screenplay Patter...

Preface In a previous article from the start of this year, I mentioned various frameworks that can be used for mobile test automation. The one that came up repeatedly was WebdriverIO, which I have been using actively for over two years now. It is a s...

Let’s be honest - who wakes up and and is excited to read button labels or error messages? But have you ever clicked a vague “Next” button and immediately regretted it because you had no idea where it was taking you? Or stared at an error message lik...

Part 1 - An Introduction to the matter What will this series be about? During this series of blog posts, I will do my best to provide my opinion on specific models, determine which use case each one fits, discuss the pros and cons of using that model...

For a customer project, we recently had to shovel a bunch of Elasticsearch data into a Kubernetes environment. Let's take a closer look at how we did that and what to watch out for.
When searching for ways to migrate between two Elasticsearch clusters we have a couple of different methods at our disposal.
Reindexing is the process of iterating over existing documents and inserting them again. This can be used to apply a different set of indexing parameters, to update the underlying index or to move the documents to a different index. This also works when considering a migration between different clusters.
When choosing this approach be aware of the following limitations:
Index mappings and aliases must be migrated manually
Puts heavy load on the cluster while reindexing every document
Index-based settings have to be copied manually
The advantage of this approach is its simplicity. It also allows you to perform an update of the index version at the same time.
This method is the only one which works without downtime. With this approach you join the new cluster nodes to the existing cluster, drain the old nodes and de-provision them after your applications all refer to the new nodes. It requires your nodes to communicate bidirectionally which might be hard to accomplish depending on your setup.
By utilizing the built-in snapshot/restore feature, we eliminate the drawbacks of the reindexing approach. Snapshots can either be taken of single indices or the entire cluster allowing for gradual migration. The downside here is the setup of a working snapshot repository. This either requires shared file storage or third-party software providing object storage capabilities.
While looking for migration options, we also evaluated elastic-dump but this did not work well for some indices. In our specific setup, it also presented a network bottleneck as data is copied to the host running the tool.
After evaluating our options and testing their viability on a smaller dataset, we decided to go with the Snapshot/Restore approach for three reasons:
We already have a working snapshot setup
Our index settings are very complex, which rules out reindexing
The data layout allows for gradual migration
The cluster we're trying to migrate contains around 605 Gi of data. Migrating this all at once would take a lot of time and since we're not able to do this without downtime, we should at least minimize it.
Our big advantage: The data in question is grouped into indices based on creation time and does not change after creation. This allows us to disable writes to old indices way ahead and move them ahead of the final migration. By moving old indices first, we can take our time for the biggest chunks of data and reduce the final downtime as only very few indices are actively being written to.
Let's get to moving around some data. For this, we first have to take a snapshot of it. Before creating the snapshot, an existing repository must be in place. In our case, we have a distributed volume available on all of our nodes so we choose this as our snapshot repository.
To create the snapshot, either use a graphical tool or issue the corresponding API request directly:
curl -X PUT "localhost:9200/_snapshot/<repository_name>/migration_snapshot?wait_for_completion=true&pretty" -H 'Content-Type: application/json' -d' {} '
This will create a snapshot called migration_snapshot. If your indices are very large, you might want to consider removing the wait_for_completion=true parameter and check on the snapshot periodically using the following API call:
curl "http://localhost:9200/_snapshot/<repository_name>/_current"
After the snapshot completes, we need a way to get this to the new cluster. The easiest way for us was to serve the contents of the backup directory using python -m http.server. If you have an RWX volume at your disposal, mounting this in all of the Elasticsearch pods is also a viable option.
To restore from this snapshot, the cluster must be configured to allow the remote host as a valid backup path. When using the ECK operator, the configuration looks something like this:
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: example-cluster
spec:
# ...
nodeSets:
- name: default
config:
repositories.url.allowed_urls: 'http://<your-remote-endpoint-including-port>'
# ...
Once this is rolled out, this URL can be used to create a new snapshot repository.
curl -X PUT "localhost:9200/_snapshot/migration_repository?pretty" -H 'Content-Type: application/json' -d'
{
"type": "url",
"settings": {
"url": "http://<your-remote-endpoint-including-port>"
}
}
'
If the configuration is applied correctly, this will create the migration_repository pointing to the remote endpoint.
To verify that everything works as expected, let's inspect the contents of the snapshot repo;
curl -X GET 'http://localhost:9200/_snapshot/migration_repository/*'
{
"snapshots": [
{
"snapshot": "migration_snapshot",
"uuid": "w1UH162UQkeDuQ0fVWyMGA",
"repository": "migration_repository",
"version_id": 7150299,
"version": "7.15.2",
"indices": [
"..."
],
"data_streams": [
],
"include_global_state": true,
"state": "SUCCESS",
"start_time": "2023-01-24T09:49:58.937Z",
"start_time_in_millis": 1674553798937,
"end_time": "2023-01-24T09:53:51.665Z",
"end_time_in_millis": 1674554031665,
"duration_in_millis": 232728,
"failures": [
],
"shards": {
"total": 833,
"failed": 0,
"successful": 833
},
},
],
"total": 1,
"remaining": 0
}
Great! If you do not see your old snapshots here, make sure that you serve the correct files. The file index.latest should be served at the root.
The last step is to import the indices of this snapshot:
curl -X POST "localhost:9200/_snapshot/migration_repository/migration_snapshot/_restore?wait_for_completion=true&pretty" -H 'Content-Type: application/json' -d'
{
"ignore_unavailable": true,
"include_global_state": true,
"include_aliases": true
}
'
Again, you can leave out the wait_for_completion=true parameter and check on the progress manually. If you want to limit the scope, provide an indices key.
And we're done! The cluster will begin routing the shards to a fitting node and your new cluster is ready to be used.