Idempotency as a concept is a key aspect of modern robust and easily recoverable systems. As such, it is important whether or not the workload under scrutiny is running in a Cloud environment or not. However, due to traits inherent to public Cloud providers, idempotency has become much more important for correctly functioning systems than it used to in on-premises systems. Hence, this article aims to shed some light on why idempotency became so important and how to implement it correctly. We are not going to reiterate documentation that is already readily available; instead, we are going to highlight the why and how on a conceptual level. After reading this article, you will know how to properly design for idempotency.
Note how many aspects covered herein are only going to occur when operating at scale. This is for technical reasons which we shall elaborate on later on. In particular, developers are unlikely to encounter the pitfalls mentioned herein when drawing on demo applications from Cloud providers. Hence, programs that are functioning just fine at small scale are going to break when put under actual load. This makes it even more important to upskill developers from the very beginning to avoid unobvious problems down the line.
The concepts presented herein will be presented with the well-known AWS Powertools for Python, but apply to other language stacks just as well.
Motivation
By definition, an operation is idempotent if its repeated execution yields the very same result. Among others, this is helpful in the following scenarios:
Deduplication
If a certain process executes based on some form of queue or bus, then idempotency ensures that duplicated messages do not lead to duplicated actions. As such, it deduplicates messages.Error Recovery
Consider a workflow consisting of stepsA -> B -> C. whereAexecuted successfully,Bfailed andCwas not executed due toB's failure. Then an engineer might investigate and fix the root problem which causedBto fail in the first place. After this fix is in place, the engineer still must ensure that the system returns to a desired state; this will usually require the entire workflow to have run successfully. If idempotency is not in place, then the engineer needs to devise a strategy on how to recover from the failed workflow. This could entailrolling back actions of
AandBand then executing from scratchrolling back
Band then restarting fromB -> C
In all cases, this is a manual process which requires investigation and effort on the engineering side, thus substantially increasing response times for production problems. Note that partial workflow execution may not be well supported by major providers, first and foremost AWS StepFunctions does not currently support this.
If idempotency is in place then the engineer fixes the underlying root problem and then simply restarts the workflow from scratch.
- Explainability
Another, rather subtle advantage, is the fact that the overall system becomes much easier to reason about. This is because idempotency forces developers to cleanly separate input, actions and output, which results in a cleaner design. We will show further down that this is not a design principle that people should follow, but rather a hard technical requirement.
Why Idempotency is now more relevant than ever
All of the aforementioned points apply to on-premises and Cloud systems alike. Now we shall briefly explain why idempotency is of particular importance in the Cloud. Due to their design, many Cloud services are prone to produce duplicates. Take the simplest possible Cloud example you could think of: subscribing a serverless function to a blob store event (in AWS parlance: S3 -> Lambda). This setup is generally going to produce duplicates, as S3 events are only guarantee to be delivered at-least-once. So if you subscribe a Lambda to S3 and have not accounted for duplicates, then you are already wrong. The underlying reason is that it is in fact very costly to ensure once-only delivery in distributed systems, hence the Cloud providers default to a better performing approach. However, this problem is not confined to the underlying platform, but also to project-level resources.
Consider scaling. For the sake of this example, we are going to assume ECS containers provisioned via Fargate. Assume that we have a container that scans a database for changes and pushes discovered changes to an event bus for downstream systems to react to. Now, assume further that a second container comes online. This is generally going to happen when a health check fails, when a new version is rolled out (to ensure business continuity) or for autoscaling. Now both instances scour the database for changes and are going to simultaneously publish the very same changes until one of them shuts down. This leads to duplicated messages in the event bus, unless special measures are taken. In this example, you can freely exchange ECS with EC2, EKS or any other relevant service.
The increased relevance is due to the fact that the Cloud is built to scale and the individual components are inherently decoupled. Where - in the past - you had a small number of servers with monolithic programs, it was in fact very hard to scale, so this problem would typically be solved on thread-level on the same machine. Difficulty in scaling made the problem less pressing, simply because there was less scaling. Nowadays, however, ideally each component in an architecture is able to scale and replicate individually, irrespective of the other components' behaviour. This means that there is a lot more room for error due to concurrency. Worse, in managed environments it is not always clear how and when components are going to scale. This brings us back to the aforementioned point; if we put a lot of load on the underlying S3 infrastructure, then it is more likely to scale, hence increasing likelihood for duplicated events in the first place. In short: a lack of idempotency is going to hit you when you start running solutions in production.
The need for a dedicated idempotency layer
Before diving deeper into specific aspects, let us shortly argue why a dedicated layer is needed. Note how many services will have built-in support for deduplication; that includes queue services like SQS on AWS, but even more fully-fledged solutions like Azure Durable Functions.
the way and scope of deduplication varies across services
In particular, you cannot assume that all services in your stack are going to support deduplication. Good examples that are likely never going to support this are databases like RDS. Note how even there is no way to makeS3itself idempotent; writing several times toS3is always going to produce several events by design - these would need to be deduplicated by downstream systems like an event bus.deduplication support is typically windowed
The time windows possible very across services and are mostly tightly limited, from minutes to a maximum of several hours.If your engineers need more time to fix a problem, you are going to be in serious trouble. There is typically no way to preserve the current state for longer.
no way to inspect current state
Depending on the problem at hand, you may want to inspect the current state of an (idempotent) operation and/or alter it to fix production problems. In particular, you might want to remove an item to restart an action that would otherwise be skipped. This is not possible in managed deduplication stores.Proprietary lock-in solutions
One of these is definitely
Azure Durable Functions. These try to solve the problem for you, but in return require you to overhaul your entire code, designing within the confines of whatever your Cloud provider deems good. In particular, theinvokerneeds to know whether or not a function is idempotent, hence seriously coupling components.
Having a common idempotency layer enables you to work in a service-agnostic way while granting you full visibility and the ability to intervene if necessary. This keeps response times low and leads to fewer problems that escalate.
Implementing idempotency
Using AWS Powertools, idempotency is a piece of cake. AWS Powertools is generally available for major language stacks like Java, .NET and Python; as it has exquisite documentation available, we only present the most important points here. In particular, to make a function idempotent, all you need to do is:
choose and/or compute an idempotency key
Each idempotency key corresponds to a unique set of parameters. Given the same parameters - and hence the same idempotency key - multiple executions of the function yield the very same result. We also say the function is idempotent with respect to a given idempotency key. This key is either given as a string or computed as a hash over a provided data structure.choose one or several idempotency backends.
Powertools supports stacking backends s.t. the quickest backend is consulted first. A typical chain would beinMemoryCache -> DynamoDB. For pipelines with much traffic, consider injecting aDynamoDB DAXinstance or - cloud-agnostic - aRedisinstance in between.choose a time window
By default, both Powertools and DynamoDB impose a TTL. This is a sensible default; evaluate for how long you want to keep this data. Note that you can always turn off item retirement to give engineers more time to fix production problems. DynamoDB is going to catch-up when you re-enable cleansing. Also note that cleansing is typically asynchronous, so that there is no guarantee of immediate retirement upon expiry.
Once you have these decisions in place, you can simply annotate your function with one of the provided annotators - and voilà, it is idempotent with respect to input:
@idempotent_function(data_keyword_argument="idempotency_key", persistence_store=persistence_layer, config=config)
def handler(record: SQSMessage, idempotency_key: SomeIdentifier):
# run some intricate logic ...
# [...]
return someResult
Note is is advisable to wrap idempotent_functionin your own decorator to retrieve persistence_storeand config from a Singleton or Identity pattern. This helps you tot keep your code DRY.
Note AWS Powertools enables you to compute the idempotency key in a variety of ways. In particular, you can leverage JSONPATH to dynamically construct new objects for usage as an idempotency key from the set of input parameters. This enables you to keep the caller agnostic of the callee being idempotent.
The overall flow - right from the official documentation - looks like this:
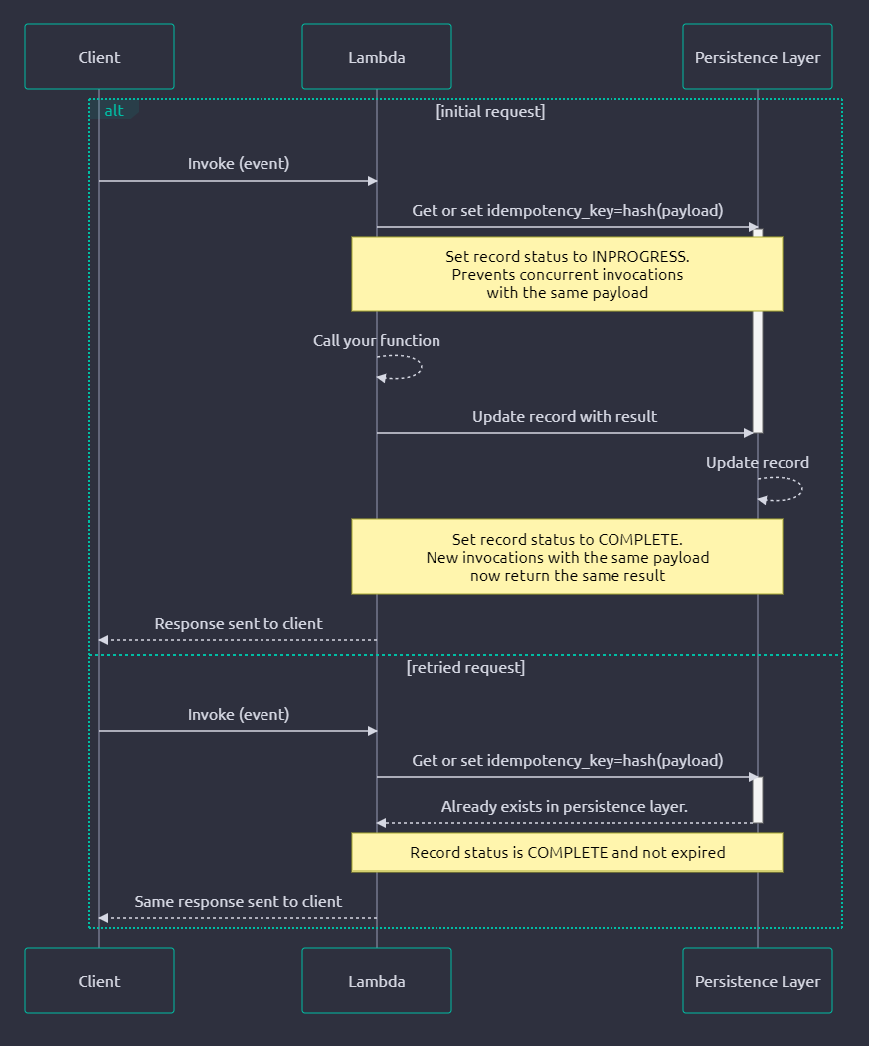
Requirements for Idempotency
The aim of this article is to empower you to design for idempotency. In particular, you need to know how to design systems s.t. they can easily be made idempotent if needed. It can be prohibitively expensive to refactor an existing codebase for idempotency. Given the emerging need as outlined above, it absolutely makes sense to design for idempotency in the first place, irrespective of an immediate need.
Idempotent functions must abide by these principles:
their payload must be serialisable to compute the idempotency key
their return value must be serialisable as the original execution context may not be available when a function is continued
the function must not have side effects owing to the original execution context not necessarily being available
Serialisability of return value
Consider the example from above: A -> B -> C. Further assume that B depends on the output of A and C on the output of B. Then, if B fails during the first execution and the engineer decides to recover by rerunning the whole workflow, then A will be skipped during the next execution. However, B is still executed and it depends on the return value of A. Hence, A's return value is persisted by the idempotency layer and passed to B upon the second execution. This typically also means that any idempotent function's return value is limited in size. Note how most idempotency stores like DynamoDB and Redis have strict limits on their item sizes.
Side effects
In the above scenario, if A, B share an execution environment (for instance: a process), any changes that Amay have made to the environment are not necessarily available to B during the second workflow execution, as B may run in a different execution environment (for instance: a process) than A. In particular, this forbids any passing of reference-holding objects, specifically (local) file resources, streams, ORM-mapped instances etc.
If all of these three requirements are met, implementing idempotency (retrospectively) becomes very straightforward. Note how these requirements enforce a clean separation between functions, hence enforcing a high level of decoupling. This also means that the mere design for idempotency increases code quality.
Choice of idempotency keys
Let us note a few important choices regarding idempotency keys.
Environments Typically, you are going to run several development environments within the same account or subscription. Depending on the cloud platform, the exact method of separation is going to differ. Still, different environments must not interfere with each other, i.e. the environment identifier should generally be part of the idempotency key.
Business Keys
Generally speaking, it is advisable to rely on business keys for idempotency key creation as much as possible. The reason is that the outcome is typically idempotent with respect to the input data, which - in turn - is typically mostly defined by its business keys. This simplifies the idempotency key construction significantly, as business keys are not subject to the behaviour of individual services in the pipeline which may or may not pass values through or regenerate them when they retry.
To give an example that is easy to grasp: consider processing a payment for a certain customer in a queue. Then, a unique paymentID (GUID) that is generated by the system is a business key. In contrast, an SQS message id that happens to be generated when that payment is flowing through an SQS queue is a technical key. Technical keys change as the flow of the data changes, when processing is retried and so on and so forth; business keys do not.
Runs
Ideally, actions are executed once and only once. However, in reality, not all downstream systems may be as well-designed as the solution you are currently building. Hence, it may be necessary for you to rerun bits of your workflow even if there is absolutely not your system at fault. To this end, it may be helpful to introduce the notion of runs.
Normally, there is only one run per business key combination, let's say run 0. If you ever need to rerun that computation, you can simply rerun it by parameterising the run with 1 ; this way, there is no need to artificially work around the idempotency mechanisms, but instead work with them.
Identifiers from upstream systems
As pointed out above, if possible, it is advisable to always rely on business keys. However, that may not be possible in all circumstances, in particular if the source does not provide stable business keys. In this case, it is advisable to rely on automatically generated, unique identifiers generated by the Cloud Platform. In this case, one can at least guarantee that the system works correctly given a certain starting point which is assumed to be reliable.
So, for instance, if we can assume that a certain message (identified by some business keys unknown to us) arrives only once to a certain SQS queue, and we generate the idempotency key from the unique SQS message identifier generated by AWS, then we can guarantee that our system works correctly from this point. Note that even in this case you may want to incorporate additional information like environments or runs (outlined above), so just relying on the automatically generated id may not be sufficient. This is often necessary when implementing fan-out.
Observability
Idempotency input is hashed into a string to produce a (hopefully unique) idempotency key. Henceforth, this one is used to ensure idempotent execution from a programmatic point of view. For operations, however, one often wants to inspect the current state of idempotency. This requires the backend to save (at least part of) the idempotency input for later inspection. While the hash is strictly limited in size, the original idempotency input is not. Therefore, it is quite prone to exceed limits posed by the idempotency backend.
Ensure to establish important information beforehand and persist it to the idempotency table while considering the size constraints. This is paramount to efficiently resolve problems with respect to idempotency.
One very straightforward approach is to label function executions with their idempotency keys, index by these and persist the respective information in the telemetry solution. These typically impose less stringent constraints and will be the point from where operators commence their debug journey in the first place. In particular, integrating with the telemetry solution enables operators to quickly establish which function invocations actually executed and which invocations were skipped due to idempotency.
Conclusion
When considered from the very beginning, it is very straightforward to design for idempotency. The article outlined a number of aspects and/or pitfalls that are best sorted before rushing into an implementation. This ensures that the system architecture is not needlessly convoluted and the recovery journey is as easy as possible. In particular, we asserted that a dedicated layer is sensible in keeping system complexity low.
Idempotency practices are best set by a platform team that provides a basis for individual development teams to build upon. This relieves individual project teams of undue mental load and ensures a coherent approach across larger platforms. In particular, it reduces the likelihood of unpleasant surprises when you want them least.